In today’s digital age, PDFs are predominantly employed by businesses and individuals for
archiving and sharing precious documents. But not all PDFs are created equal. Some are
simple image-based documents, and others contain text extracted via Optical Character
Recognition (OCR). It is worth knowing whether a PDF has gone through OCR processing,
especially for data extraction activities, searchability, and automation.
We will explain various methods through which one can verify whether a PDF has been
processed via OCR or not, the role of AI & ML solutions in it, and the role played by computer
vision in document intelligence in this article.
What is OCR?
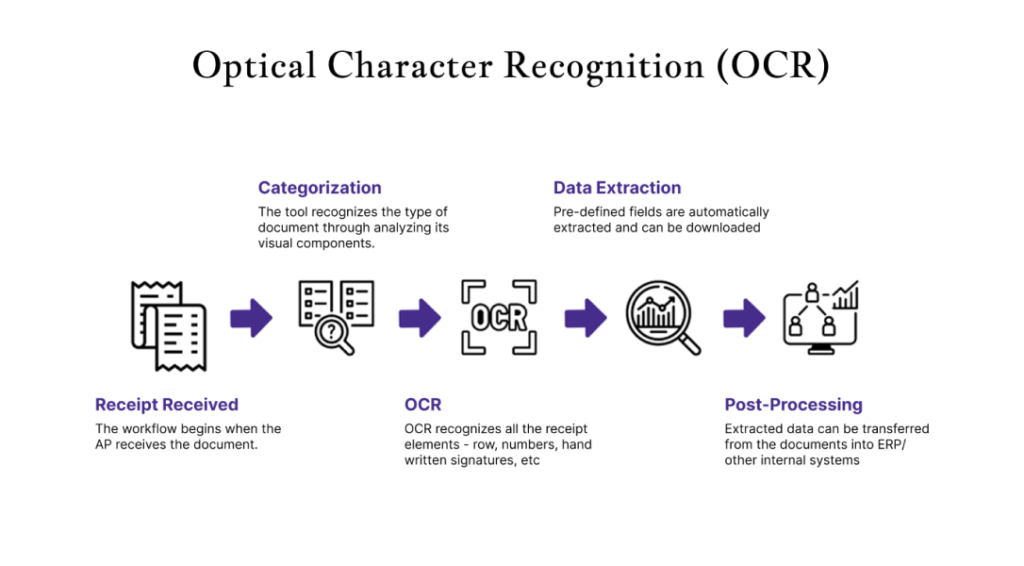
Optical character recognition (OCR) is the innovative assertion that reads printed or handwritten
text into digital texts. It gives computers the power to extract and process any sort of text from
images or scanned documents. It is one of the widely used technologies in digitization of
documents, automation of data entry, and text recognition applications. Advanced OCR systems
use AI and machine learning to improve the precision and legibility of the output. Such image
files can be electronically made readable texts through Optical Character Recognition (OCR)
technology. Users generally can’t easily search for data and copy and analyze texts from image
PDF formats. OCR technology has developed at an extremely rapid rate over the years, with
significant improvements in artificial intelligence and machine learning. There are two primary
forms of PDFs:
● Image-based PDFs: These contain only text images and require OCR to be converted
into machine-readable text.
● OCR PDFs (Searchable PDFs): These are already OCR’d and can be searched and
text pulled out of them.
Why is it Necessary to Know Whether a PDF is OCR?
It is necessary to know whether a PDF is OCR-processed for several reasons:
Searchability: OCR-processed PDFs are searchable, making document retrieval convenient.
Automation: Structured text is needed by AI-driven automation tools to extract information
from PDFs.
Accessibility: OCR makes documents more accessible to users who use screen readers.
Data Processing: Companies handling bulk document processing need OCR to process and
extract data effectively.
Given these benefits, ensuring a PDF is OCR-enabled can significantly improve workflow
efficiency.
Ways to Find out if a PDF is OCR
There are many ways to verify if a PDF is OCR. Here are some of the most useful ways:
1. Attempt to Select the Text
You can infer if a PDF has been OCR-scanned or not by selecting the text.
● Try highlighting a word or sentence in the PDF.
● If it does allow copy-pasting text into any other document, then it has been
put through OCR.
● If it cannot be highlighted, then it is an image-based PDF.
2. Use the Search Function
● Open up the PDF and then hit Ctrl +F (Windows) or Command +F (Mac).
● Enter a keyword that is in the document.
● If the search function is able to find the keyword, the PDF has searchable text, i.e., it has
been OCR-processed.
● If nothing comes up, then it is probably an image-based PDF.
3. Check the Document Properties
OCR will be disabled when document properties are made hidden vp..
● Open the PDF using Adobe Acrobat Reader.
● Go to File > Properties.
● Search for it in the Description or Fonts menu. If text-based fonts are found, the PDF is
OCR-processed.
4. Employ Online OCR Detection Tools
Several online tools and software solutions can help determine if a PDF has undergone OCR.
Some tools analyze the document structure and identify text layers within the file.
5. AI & ML-Based Detection
Sophisticated AI & ML tools, including ML Bench, apply deep learning and computer vision to
identify whether a PDF is OCR-processed. Such tools can scan documents automatically,
identify text layers, and offer analysis of OCR processing quality. Organizations handling large
PDFs can apply AI-based tools to automate document processing processes.
The AI & ML Role in OCR Detection
With the advent of machine learning and artificial intelligence, OCR technology became more
sophisticated and precise. Deep learning models along with natural language processing (NLP)
aid OCR solutions by AI.
● Improve text recognition accuracy
● Identify and process complex fonts and handwriting
● Enhance low-quality scans for better OCR results
● Enable intelligent document classification and data extraction
Computer Vision’s Impact on OCR
Computer vision is an important aspect of OCR technology. It allows systems to:
● Identify text in images
● Examine document layouts
● Identify patterns in handwritten and printed text
● Translate image-based content into machine-readable formats
Companies improve OCR with AI and computer vision, allowing for more efficient management
of document-based processes.
Conclusion
It is essential to detect whether a PDF has gone through OCR-processing for text searchability,
automation, and data retrieval. Users can simply check if a PDF contains searchable text or
handwriting by implementing simple processes such as text selection, search commands, and
AI-based detecting tools.
With AI & ML technology, OCR continues to develop with more accurate and efficient document
processing features. Whether you’re processing business documents or scanning archives,
using AI-based OCR solutions can greatly streamline your workflow and productivity.
If you work with bulk document processing, think about using AI-based tools such as ML Bench
to automate OCR detection and enhance document intelligence

